
Why the biggest barrier to a second location is not money
Twelve weeks ago, this series started with a single question: what does free roam actually mean? Not as a marketing concept, but as a live operating system with moving parts, competing demands, and very little margin for error once customers are in the space.
Every week since has added another layer. Tracking. Networking. Calibration. Content licensing. Staff cycles. Session automation. Each topic, its own problem. Each solved problem, a prerequisite for the next.
This final week asks the natural follow-on question: what happens when it works at one location, and you want to do it again somewhere else?
The honest answer is that most operators who reach this point are not prepared for how different the question becomes.
Replication Is Not the Same as Repetition
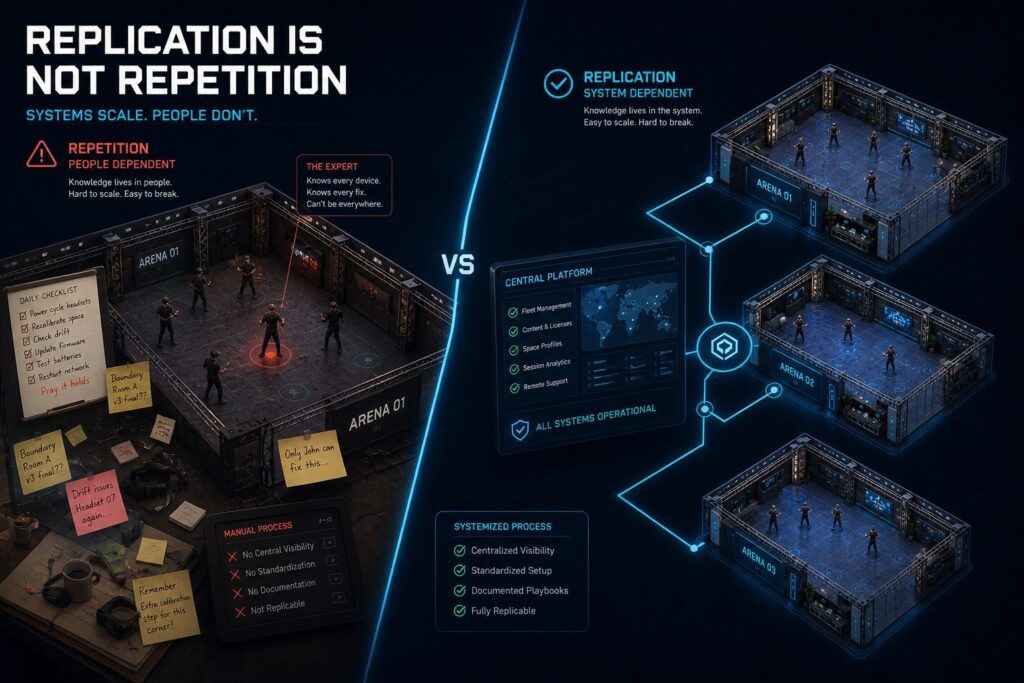
Opening a second location feels like proof of success. Revenue is stable at the first site. Demand is real. The model works. Expansion seems like the logical next step.
What changes at location two is the nature of the business entirely. A single-site operation can survive on proximity, informal communication, and the founder being present when something breaks. A two-site operation cannot share any of those things. What worked because you were there will not work because your manager is there instead, unless you have converted everything you know into something they can follow without you.
Often scaling failures are caused by systems that were never designed to scale, not necessarily caused by a lack of ambition or capital.
This is not a VR-specific problem. It is a universal truth about physical operations. The franchise industry has been running this experiment at scale for decades. The data is not encouraging: only 16% of franchisors ever reach the 100-location milestone. The median number of franchise locations is 38. The vast majority of operators who attempt multi-location expansion stall before they get there.
The reason is consistent across industries: the operation was built for one location, optimized for one location, and was never designed to be replicated. It worked because of specific people in a specific place making specific daily decisions that existed nowhere except in their heads.
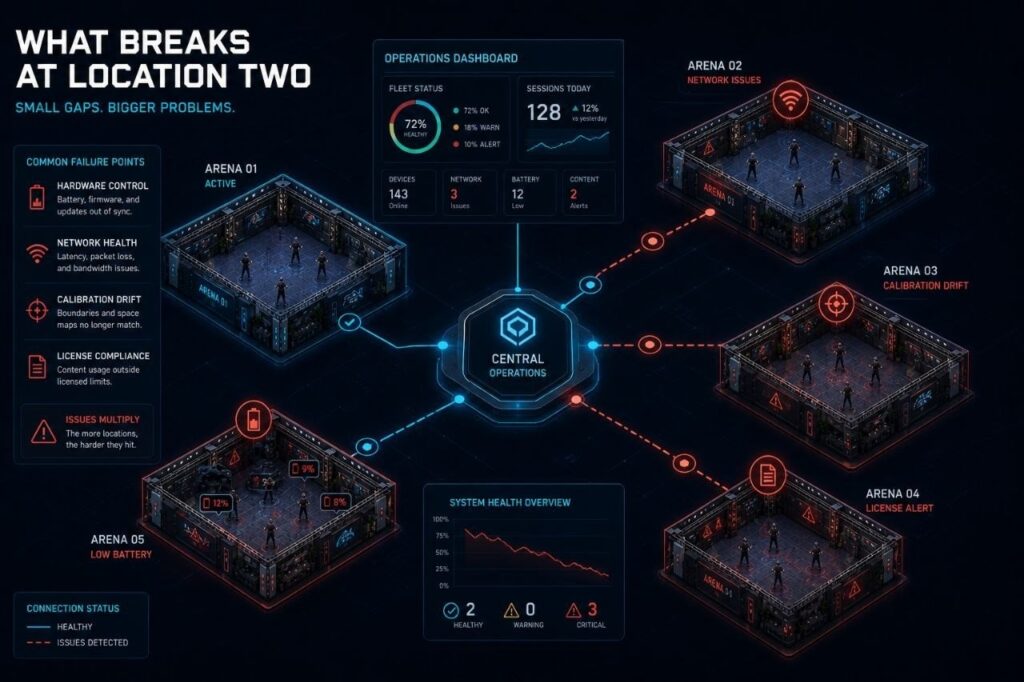
What Actually Breaks at Location Two
In a VR arena context, the failure points are predictable once you know what to look for. They are not dramatic. Nobody walks in one morning to find the business has collapsed. Instead, a series of small, reasonable decisions compound into a structural gap between how fast you are growing and how well your operations can keep up.
Here is what typically breaks:
Hardware control
At one location, a fleet is manageable through familiarity. The manager knows each headset, knows which ones drift, knows which require an extra calibration step. At two locations, that knowledge does not transfer. Without centralized visibility across both sites, firmware changes, battery status, and device behavior become invisible problems. A consumer headset update that changes the operating environment overnight is a manageable inconvenience at one site. At three sites, it is an operational failure.
Calibration and environment profiles
Operators who solved calibration at location one by storing boundary data and space maps in a centralized system open a second location with a replicable asset. Operators who solved it by having one skilled staff member walk the space every morning have built something that cannot be reproduced. They have to rebuild it from zero, every time, at every new site.
Content licensing compliance
A single location can handle licensing informally when the operator knows the catalog and tracks usage personally. Add a second location, and the compliance surface doubles. Add a third, and the problem is no longer manageable without a platform that tracks usage across all sites and keeps every location within its licensing terms automatically. Operators who discovered this late have rarely found it cheap to fix.
Staff dependency
This one is the most common failure point and the hardest to diagnose in advance. A single location can survive on one expert employee who knows the system. That employee cannot be in two places at once. A second location staffed by people who are learning the operation through verbal instructions rather than documented systems will not run the same experience. It will run a rough approximation of it, degrading further with every staff turnover cycle.
OPERATOR REALITY CHECK
The biggest barrier to expansion is not money. It is inconsistency. A location that cannot reproduce the same setup twice will struggle to reproduce it ten times. The operators who scale successfully are almost never the ones with the most capital. They are the ones who treated their first location as a system to be documented, not a business to be managed by feel.
The Difference Between a Venue and a System
There is a version of a VR arcade that is a place. The owner knows it intimately. Staff figure things out. Sessions work because experienced people are present and paying attention. That version is not scalable.
There is another version that is a system. Setup is documented. Staff follow a process, not a person. Hardware is monitored centrally. Content is licensed and tracked automatically. Session launch does not depend on which employee is working that shift. That version can be reproduced.
The difference between them is not technology. It is whether the operational knowledge that lives in people has been extracted and built into processes that survive staff turnover, absent founders, and new locations that have never seen the original.
Firms that scale smoothly have playbooks. The ones that don’t end up with multiple locations that each operate like independent businesses sharing a name.
Operators who have watched franchise models attempt to take hold in this industry over the years will recognize the pattern. We have seen enough of these attempts to know that the limiting factor is rarely ambition or capital. It is almost always the absence of a replicable system.
The first location is often strong. The jump to a second or third exposes the gaps: operations that lived in people rather than processes, setup procedures that were never written down because the founder was always on site, licensing arrangements that were never structured for multi-site compliance.
The ambition was real however, the system was not ready.
Centralized Control Is Not Optional at Scale
Managing two locations from memory is possible. Managing five is not. The shift from single-site to multi-site operation requires visibility that does not exist without infrastructure.
At scale, operators need to know the status of every headset at every location without making a phone call. They need to push a content update across all sites simultaneously without sending instructions to each manager individually. They need to see session data, battery levels, network health, and booking performance from a single dashboard, regardless of which site they are physically in.
This is not a convenience feature. It is the operational prerequisite for making decisions at the speed that multi-location management requires. Without it, a problem at location three is already a full incident before anyone at the central level knows it exists.
The operators who build this infrastructure before they need it are the ones who scale. The ones who build it after they have already opened three locations spend the first year of their expansion fixing problems that the infrastructure would have prevented.
What the Last Eleven Weeks Were Actually Building
Looking back at this series, every topic was a prerequisite for this one.
Week 1 established that free roam is a live system, not a play area. Systems require management infrastructure, not just hardware.
Week 2 identified the consumer trap: devices that cannot be controlled centrally are not compatible with multi-location operations at any scale.
Week 3 examined why enterprise hardware matters, and the answer was always the same: control, consistency, replicability.
Weeks 4 through Week 11 built the operational stack: space design, networking, calibration, session automation, staff training, content licensing, performance benchmarking. Every one of these areas has a version that works at one location and a version that works at ten. The difference is always the same. One version depends on people. The other depends on systems.
An LBE VR platform built for multi-location VR management handles the parts that do not scale manually: fleet visibility across all sites, boundary profiles stored and deployed centrally, content licensing tracked automatically across every headset at every location, session launch automated so that staff competency does not determine session quality. When a second or third location opens, the setup is not rebuilt from zero. It is replicated from a platform that was already running it.
That is the difference between 400 venues operating on the same system and 400 venues each solving the same problems independently.
THE CONCLUSION THE SERIES WAS ALWAYS BUILDING TOWARD
Scaling free roam VR successfully requires a platform designed for replication, not improvisation. Every operational problem this series addressed becomes harder to manage manually as location count grows. The operators who built their first arena on centralized management infrastructure did not just solve a single-location problem. They built the foundation for every location that follows.
DEMO SYNTHESISVR ON PICO HARDWARE
Stop fighting your hardware. Start operating your business. See how the PICO 4 Ultra Enterprise and SynthesisVR work together to solve:
- Manual sync: one-click launch for the entire fleet
- Drift and mapping: instant boundary sharing across all headsets
- Operational visibility: monitor devices, network, and battery life from one system
- Multi-location management: the same dashboard works at two locations or twenty
Try SynthesisVR now, No Card Required!
Built by operators, for operators. Trusted by 600+ locations.









